Pour tous ceux qui sont intéressés au domaine des réseaux informatiques & la sécurité !
.
L'encapsulation
L'encapsulation Chaque couche du modèle OSI a une fonction déterminée. Nous avons vu que
la couche en cours utilise les services de la couche au-dessous d’elle
qui, à son tour, en offre pour la couche du dessous. Cette corrélation
indique bien que certaines informations peuvent se retrouver d'une
couche à une autre. Cela n’est possible que grâce au principe
d’encapsulation. L’encapsulation consiste à encapsuler
En d'autres termes, elle consiste à envelopper les données à chaque couche du modèle OSI.
Quand
vous écrivez une lettre (pas un mail), vous devez la glisser dans une
enveloppe. C’est à peu près le même principe dans le modèle OSI : les
données sont enveloppées à chaque couche et le nom de l’unité de données
n'est rien d'autre que le nom de l’enveloppe. Nous avons vu dans la
sous-partie précédente que, dans la couche applicative, l’unité de
données était l’APDU (ou plus simplement le PDU). Ensuite, nous avons vu
que dans la couche réseau, l’unité de données était le paquet. Ces PDU
forment une sorte d'enveloppe qui contient deux choses : la donnée en
elle-même et l’en-tête spécifique à cette couche. La partie « donnée »
de ce paquet est composée de la donnée initiale, mais aussi des en-têtes
des couches qui la précèdent. Il existe une toute petite formule
mathématique définissant la relation entre les couches. Ce n’est pas
difficile, pas la peine de fuir !
Considérons l’image ci-dessous :
Soit C une couche du modèle OSI. La couche C + 1 utilise les services de
la couche C. Facile, n’est-ce pas ? La couche session utilise les
services de la couche transport, par exemple. La donnée que la couche C +
1 transmet à la couche C est appelée SDU tant qu’elle n’a pas encore
été encapsulée par cette dernière. Si, par contre, la couche C encapsule
ce SDU, on l’appelle désormais… PDU.
Quelle est donc la relation entre le PDU et le SDU ?
Dans une couche C, le
PDU est le SDU de la couche C + 1 plus son en-tête (couche C). Ce SDU ne
devient un PDU qu'après l’encapsulation. La couche C ajoute des
informations dans l’en-tête (header) ou le pied (trailer),
voire les deux, du SDU afin de le transformer en un PDU. Ce PDU sera
alors le SDU de la couche C - 1. Donc le PDU est un SDU encapsulé avec
un en-tête.
Voici la constitution d'un PDU :
trailer (pied de la trame) c'est juste pour la correction des erreurs par exemple ! (CRC)
Comprendre la relation entre un SDU et un PDU peut être complexe. Pour
vous simplifier la tâche, nous allons considérer un exemple inspiré du
monde réel et vous aurez ensuite droit à un schéma.
Quand vous écrivez une
(vraie) lettre, c'est un SDU. Vous la mettez dans une enveloppe sur
laquelle est écrite une adresse. Cette lettre qui n’était qu’un SDU
devient un PDU du fait qu’elle a été enveloppée (encapsulée). Votre
lettre arrive à la poste. Un agent du service postal regarde le code
postal du destinataire et place la lettre dans un sac. Mais on ne la
voit plus, puisqu’elle est dans un sac. Pour l'instant, la lettre,
l’enveloppe et le sac forment un SDU. L’agent du service postal va alors
inscrire le code postal du destinataire sur le sac en question, qui
devient donc un PDU. S'il contient d’autres lettres partant pour la même
ville, elles seront alors toutes mises dans une caisse : c’est un SDU.
Tout comme on a ajouté des informations sur l’enveloppe et sur le sac,
il faut également mettre un code postal sur la caisse. Cet ajout fait de
cette caisse un PDU.
Voilà
pour la procédure de transmission. Mais pour la réception, les sacs à
l’intérieur de la caisse (des SDU) sont enlevés lorsqu'elle atteint sa
destination. Attention, c’est ici que vous devez être très attentif/attentive. Si un individu prend un sac et en lit le code postal pour l’acheminer à son destinataire, le sac n’est plus
considéré comme un SDU mais comme un PDU. C’était un SDU au moment de
sa sortie de la caisse. Étant donné qu’il y a des informations de plus
sur le sac, c’est un PDU pour celui qui les lit.
Lorsque
le destinataire recevra la lettre, les informations ajoutées sur le sac
ou sur la caisse ne seront plus visibles : il ne restera plus qu’une
enveloppe contenant la lettre originale (un SDU).
Tenez, un schéma illustrant l'encapsulation des SDU dans le modèle OSI :
Dans le schéma ci-dessus, DF signifie Data link Footer. Le
terme n'est pas exact, mais nous l’utilisons pour faciliter votre
compréhension. Le vrai terme français qui équivaut au mot trailer
est « remorque ». Une remorque est un genre de véhicule que l’on attèle
à un autre véhicule ; la remorque est en quelque sorte la queue ou le footer du véhicule principal. Il est donc plus facile d'utiliser footer plutôt que trailer ; le mot pied plutôt que remorque.
Tous les éléments encadrés en or forment un SDU, comme le stipule la légende.
Comme vous le voyez, au début nous n’avons que les données initiales,
que l’on pourrait également appeler données d’application. La donnée
initiale à ce stade est un SDU. Une fois dans la couche applicative, un
en-tête AH (Application Header : « en-tête d’application ») est
ajouté à cette donnée initiale. La donnée de la couche applicative est
un APDU. La couche applicative transmet cela à la couche de présentation
au-dessous. Cette donnée transmise est un SDU. Par l’encapsulation,
cette couche ajoute un en-tête PH au SDU de la couche applicative. La
couche de présentation envoie ce « nouveau » message à la couche de
session et cette dernière encapsule son header avec le SDU
obtenu de la couche présentation pour former son SPDU. Et ainsi de suite
jusqu’à la couche liaison, qui a la particularité d’ajouter également
un trailer. Finalement, toutes ces données sont converties en une série de bits et mises sur le média pour la transmission.
Une couche ne doit pas connaître (ne connaît pas) l’existence de
l’en-tête ajouté par la couche au-dessus d’elle (la couche C + 1). En
fait, cet en-tête, par l’encapsulation, apparaît comme faisant partie
intégrante de la donnée initiale. Par conséquent, la couche ignore qu'il
s'agit d'un en-tête, mais elle le considère comme appartenant aux
données à transmettre.
Vous pouvez également constater que toutes les informations ajoutées
dans la couche supérieure se retrouvent dans la couche inférieure. Ainsi
dans la couche réseau, par exemple, on retrouve la donnée initiale +
l’en-tête d’application (AH) + PH + SH + TH. Toutes ces « informations »
seront considérées par la couche réseau comme la donnée initiale. Dans
cet exemple, la couche réseau ne s’occupe donc que de son propre
en-tête.
Si, à chaque couche, l’en-tête est ajouté à la donnée initiale, ne serait-ce pas compromettre l’intégralité du message ?
très belle question !! Chaque couche ajoute à la donnée initiale un en-tête. De la sorte, tous
les en-têtes sont réunis dans la couche de liaison. Lorsque ces
informations seront converties en une suite de bits, le récepteur
devrait recevoir des données erronées puisque la donnée initiale n’avait
pas tous ces en-têtes, n’est-ce pas ? En principe. Mais le modèle OSI
(ou le modèle TCP/IP) est assez intelligent. En effet, dans la procédure
de réception, chaque en-tête est enlevé lorsque le message « grimpe »
les couches, tel qu’illustré par le schéma ci-dessous. Cette «
suppression » d’en-tête, c’est la décapsulation !
Comme vous le voyez sur le schéma, dans la procédure de réception, chaque couche supprime son en-tête correspondant après l’avoir lu. Par exemple, l’en-tête NH (réseau) est supprimé dans la couche réseau de l’hôte récepteur après que ce dernier l’a lu. important : dans la couche 4 on utilise la notion de multiplexage et démultiplexage (un type d'encapsulation) pour assigner des ports à des applications (de la couche application) et on utilise la notion des sockets et les protocoles de transport UDP et TCP. exemple :
en réseau, un socket sert donc à faire communiquer un processus avec un
service qui gère le réseau. Chaque socket a une adresse de socket. Cette
adresse est constituée de deux choses : une adresse IP et un numéro de
port. C'est grâce à la programmation de socket que l'on définit le
modèle de communication. Si le socket a été configuré de manière à
envoyer ou recevoir, c'est un modèle Half-Duplex. S'il a été configuré de manière à envoyer et recevoir simultanément, il s'agit d'un modèle Full-Duplex.
Étant donné que les sockets sont en fait une interface de programmation
d'applications (API), on peut donc s'en servir pour programmer des
applications en réseaux (par exemple, créer une application pour faire
communiquer un client et un serveur) voici un schéma illustrant une communication entre un client et un serveur.
Le schéma en lui-même est assez explicite, mais nous allons vous guider afin de bien le comprendre.
Le client commence à se connecter au serveur grâce aux sockets. Une
fois la connexion établie (étape 1), le client et le serveur peuvent
communiquer (s'échanger des messages). C'est ce qui se passe dans les
étapes 2 et 3. À la fin de la communication, le client envoie une
demande de terminaison de session au serveur (étape 4) et le serveur met
fin à la connexion Mais avant tout cela, vous remarquerez que le serveur n'effectue pas les
mêmes actions initiales que le client. Le serveur utilise les sockets
pour lier un port d'application à son processus correspondant. Ensuite,
il « écoute » ce port. « Écouter », ici, c'est « continuellement
vérifier s'il y a un événement qui se passe sur ce port précis ». Ce
faisant, il va découvrir qu'un client essaie de se connecter à lui par
le numéro de port qu'il écoute. Il accepte donc la requête, établit la
connexion (étape 1) et, finalement, les deux communiquent (étapes 2, 3
et 4). Le modèle de communication est Half-Duplex parce que le client envoie et attend la réponse du serveur et vice-versa.
Les fonctions des API
Comme vous le savez
dorénavant, la programmation des sockets se fait par le biais d'une API
(Interface de Programmation d'Application). Il existe plusieurs API pour
programmer les sockets ; l'une des plus populaires est Winsock. Cependant, chaque API propose les fonctions suivantes :
socket()
: dans le schéma, vous voyez bien que la première case est « socket ».
Cette fonction crée un objet de type Socket que l'on peut identifier par
un nombre entier. La création de cet objet, bien entendu, nécessite
l'allocation de ressources (mémoire) pour cet objet.
bind()
: en français, ça veut dire « lier ». Au niveau du serveur, dans le
schéma, nous avons mis « liaison » juste après socket. Ainsi, après
avoir créé une nouvelle instance d'un objet de type Socket, au niveau du
serveur, il faut utiliser la fonction bind() pour lier ou associer un
socket à une adresse de socket (IP + port).
listen()
: cette fonction est également utilisée au niveau du serveur. Dans le
schéma, c'est le bloc « écoute ». Cette fonction change l'état du socket
et le met dans un état d'écoute. Comme nous l'avons expliqué, le
serveur va « écouter » l'adresse à laquelle est associé le socket en
attendant un événement. Il y a également une fonction poll() qui agit
aussi dans le même but que la fonction listen(), mais d'une manière
différente.
connect()
: cette fonction permet au client d'établir une connexion avec le
serveur. En général, ça sera une connexion TCP, car la majorité des
sockets utilisent TCP comme protocole de transmission. Cette fonction
assigne également un numéro de port local au socket coté client.
accept()
: en toute logique, cette fonction sera appelée du côté du serveur, car
elle sert principalement à accepter une requête de connexion envoyée
par le client.
send()
: cette fonction, qui signifie « envoyer » et qui est également
représentée dans le schéma (bloc « envoi »), sert à envoyer des données
du client au serveur et vice-versa. On utilise également la fonction
write() (écrire) ou sendto() (envoyer à).
recv()
: cette fonction, représentée par le bloc « réception » du schéma, sert
à recevoir les données envoyées par la fonction send(). On utilise
également la fonction read() (lire) ou recvfrom() (recevoir de).
close()
: c'est la fonction qui permet au système d'exploitation de libérer les
ressources allouées lors de la création de l'objet de type Socket avec
la fonction socket(). C'est donc la terminaison de la connexion. Elle
est représentée par le bloc « fin » dans notre schéma.
les protocoles TCP et UDP
UDP
Le User Datagram Protocol (UDP, en français protocole de datagramme utilisateur) est un des principaux protocoles de télécommunication utilisés par Internet. Il fait partie de la couche transport
Le rôle de ce protocole est de permettre la transmission de données
de manière très simple entre deux entités, chacune étant définie par une
adresse IP et un numéro de port. Contrairement au protocole TCP, il fonctionne sans négociation : il n'existe pas de procédure de connexion préalable à l'envoi des données (le handshaking). Donc UDP ne garantit pas la bonne livraison des datagrammes à destination, ni leur ordre d'arrivée. Il est également possible que des datagrammes soient reçus en plusieurs exemplaires. L'intégrité des données est assurée par une somme de contrôle sur l'en-tête. L'utilisation de cette somme est cependant facultative en IPv4 mais obligatoire avec IPv6.
Si un hôte n'a pas calculé la somme de contrôle d'un datagramme émis,
la valeur de celle-ci est fixée à zéro. La somme de contrôle inclut les
adresses IP source et destination. La nature de UDP le rend utile pour transmettre rapidement de petites
quantités de données, depuis un serveur vers de nombreux clients ou
bien dans des cas où la perte d'un datagramme est moins gênante que
l'attente de sa retransmission. Le DNS, la voix sur IP ou les jeux en ligne sont des utilisateurs typiques de ce protocole. UDP est un protocole orienté "non connexion". Pour faire simple,
lorsqu'une machine A envoie des paquets à destination d'une machine B,
ce flux est unidirectionnel. En effet, la transmission des données se
fait sans prévenir le destinataire (la machine B), et le destinataire
reçoit les données sans effectuer d'accusé de réception vers l'émetteur
(la machine A). Ceci est dû au fait que l'encapsulation des données
envoyées par le protocole UDP ne permet pas de transmettre les
informations concernant l'émetteur. De ce fait, le destinataire ne
connait pas l'émetteur des données hormis son IP.
Structure d'un datagramme UDP
Il contient les quatre champs suivants :
Port Source : indique depuis quel port le paquet a été envoyé.
Port de Destination : indique à quel port le paquet doit être envoyé.
Longueur : indique la longueur totale (exprimée en octets) du segment UDP (en-tête et données). La longueur minimale est donc de 8 octets (taille de l'en-tête).
Somme de contrôle : celle-ci permet de s'assurer de l'intégrité du paquet reçu quand
elle est différente de zéro. Elle est calculée sur l'ensemble de
l'en-tête UDP et des données, mais aussi sur un pseudo en-tête (extrait
de l'en-tête IP)
TCP
Transmission Control Protocol (littéralement, « protocole de contrôle de transmissions ») abrégé TCP, est un protocole de transport fiable, en mode connecté
Contrairement à l'UDP, le TCP est orienté "connexion". Lorsqu'une
machine A envoie des données vers une machine B, la machine B est
prévenue de l'arrivée des données, et témoigne de la bonne réception de
ces données par un accusé de réception. Ici, intervient le contrôle CRC
des données. Celui-ci repose sur une équation mathématique, permettant
de vérifier l'intégrité des données transmises. Ainsi, si les données
reçues sont corrompues, le protocole TCP permet aux destinataires de
demander à l'émetteur de renvoyer les données corrompues.
Structure d'un segment TCP
Signification des champs :
Port source : numéro du port source
Port destination : numéro du port destination
Numéro de séquence : numéro de séquence du premier octet de ce segment
Numéro d'acquittement : numéro de séquence du prochain octet attendu
Taille de l'en-tête : longueur de l'en-tête en mots de 32 bits (les options font partie de l'en-tête)
Drapeaux
Réservé : réservé pour un usage futur
ECN : signale la présence de congestion
URG : Signale la présence de données urgentes
ACK : signale que le paquet est un accusé de réception (acknowledgement)
PSH : données à envoyer tout de suite (push)
RST : rupture anormale de la connexion (reset)
SYN : demande de synchronisation (SYN) ou établissement de connexion
FIN : demande la FIN de la connexion
Fenêtre : taille de fenêtre demandée, c'est-à-dire le nombre
d'octets que le récepteur souhaite recevoir sans accusé de réception
Checksum : somme de contrôle calculée sur l'ensemble de l'en-tête
TCP et des données, mais aussi sur un pseudo en-tête (extrait de
l'en-tête IP)
Pointeur de données urgentes : position relative des dernières données urgentes
Options : facultatives
Remplissage : zéros ajoutés pour aligner les champs suivants du paquet sur 32 bits, si nécessaire
Données : séquences d'octets transmis par l'application
Voici un schéma de Socket qui représente la communication en mode non connecté (UCP)







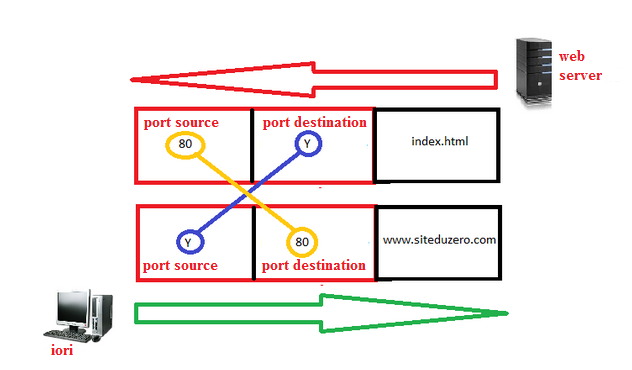
 Le schéma en lui-même est assez explicite, mais nous allons vous guider afin de bien le comprendre.
Le schéma en lui-même est assez explicite, mais nous allons vous guider afin de bien le comprendre.

